
- 什么是特征工程当中的无量纲化? 为什么要做无量纲化?
从原始数据中提取特征以供算法和模型使用。通过总结和归纳,人们认为特征工程包括以下几个方面:
无量纲化使不同规格的数据转化到同一规格, 常用方法:
- 标准化和区间缩放法
- 标准化的前提是特征服从正态分布。
为什么标准化要求区间符合符合正态分布?
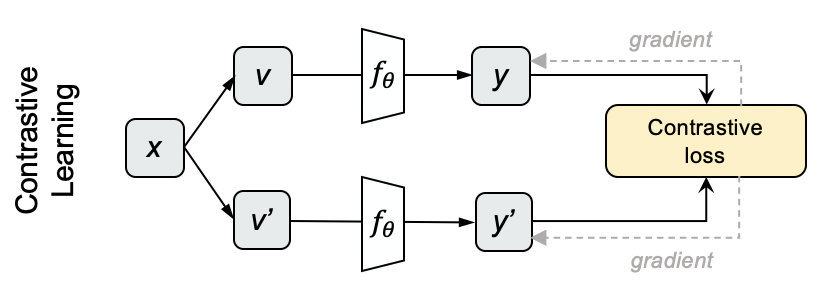
从原始数据中提取特征以供算法和模型使用。通过总结和归纳,人们认为特征工程包括以下几个方面:
无量纲化使不同规格的数据转化到同一规格, 常用方法:
为什么标准化要求区间符合符合正态分布?
记录一次数据下跌的排查
ROC曲线的全称是(receiver operating characteristic curve), 反应敏感性和特异性连续变量的的综合指标。
那么什么是敏感度(sensitivity)? 什么是特异度(specificity)? 对负样本的分类准确率, 对正样本的分类准确率。
特异度(specificity)与灵敏度(sensitivity 糖尿病人的例子
specificity: 是指对负样本识别的特异度, 负样本识别的比率高, 特异度越高。 TN / (TN + FP) sensitivity: 表示对正样本识别的敏感度, 正样本识别的比率高, 敏感度越高。
ROC曲线的横轴是: 1 - specificity ROC曲线的纵轴是: sensitivity
TP / (TP + FN)
ROC曲线是怎么绘制的
选择不同的分类阈值, 然后根据这些阈值分别计算sensitivity和 specificity
我们假设两种极端情况:
那么, 我们可以得到ROC曲线下的面积其实可以表示模型分类的效果。
AUC的全称(Area under curve)
其中$rank_{ins_i}$表示正样本在所有样本中的排序值, $M$ 表示正样本个数, $N$ 表示负样本个数。
struct RECORD {
float label;
float predict;
float weight;
RECORD(float label_y, float predict_y, float sample_weight = 1.0):
label(label_y), predict(predict_y), weight(sample_weight) {}
bool operator<(RECORD &i) { return predict < i.predict; }
};
首先定义了一个RECORD的结构体, 这个结构体包含三个部分:
for (size_t i = 0; i < predicts.size(); ++i) {
if (weights.empty()) {
id_list_result[group_ids[i]].push_back(
AucCalc::RECORD(labels[i], predicts[i]));
} else {
id_list_result[group_ids[i]].push_back(
AucCalc::RECORD(labels[i], predicts[i], weights[i]));
}
}
struct RetAucInfo {
RetAucInfo() : area(0.0), auc(0.0), weighted_postive_num(0.0),
weighted_negative_num(0.0) {}
// area is the intermediate value for distributed auc
double area;
double auc;
double weighted_postive_num;
double weighted_negative_num;
SampleStatisticInfo sample_info;
};
struct SampleStatisticInfo {
SampleStatisticInfo() : predict_sum(0.0), postive_num(0), negative_num(0) {}
void Reset() {
predict_sum = 0.0;
postive_num = 0;
negative_num = 0;
}
double predict_sum;
uint64_t postive_num;
uint64_t negative_num;
};
在RetAucInfo这个结构体里面有三个字段, 在不考虑权重的情况下:
整体AUC的计算在以下代码中完成。
bool AucCalc::CalcLocalAuc(
const std::list<RECORD> &list_result, RetAucInfo& out) {
double weighted_postive_num = 0;
double weighted_negative_num = 0;
double predict_sum = 0.0;
uint64_t postive_num = 0;
uint64_t negative_num = 0;
for (auto next = list_result.begin(); next != list_result.end(); next++) {
if (next->label == 1) {
weighted_postive_num += next->weight;
postive_num++;
} else {
weighted_negative_num += next->weight;
negative_num++;
}
predict_sum += next->predict;
} // for next
double total_area = weighted_postive_num * weighted_negative_num;
out.weighted_postive_num = weighted_postive_num;
out.sample_info.predict_sum = predict_sum;
out.sample_info.postive_num = postive_num;
out.sample_info.negative_num = negative_num;
if (total_area == 0) {
NUMEROUS_ERROR << "fail to calculate auc, weighted_postive_num: "
<< weighted_postive_num << ", weighted_negative_num: "
<< weighted_negative_num;
return false;
}
double h = 0;
double area = 0;
std::string label_before = "";
std::string next_weight = "";
for (auto next = list_result.rbegin(); next != list_result.rend(); next++) {
label_before += std::to_string(next->label) + " ";
next_weight += std::to_string(next->weight) + " ";
if (next->label == 1) {
h += next->weight;
} else {
area += (h * next->weight);
}
}
什么是ECPM
记录一次数据下跌的排查
问题1: 讨论的目的? 问题2: 表达的形式? 线上还是线下? 问题3: 讨论的内容? 是不是要有门槛,
能够Cover到的部分:
不能Cover到的部分:
这4份数据里面, 数据1和数据2是原始数据, 数据3和数据4是派生数据。
主要在于节点编码: [ns_config] node_name=[””, “”, “”, “”] ugc_node=[””, “”, “”, “”]
[ns_code]