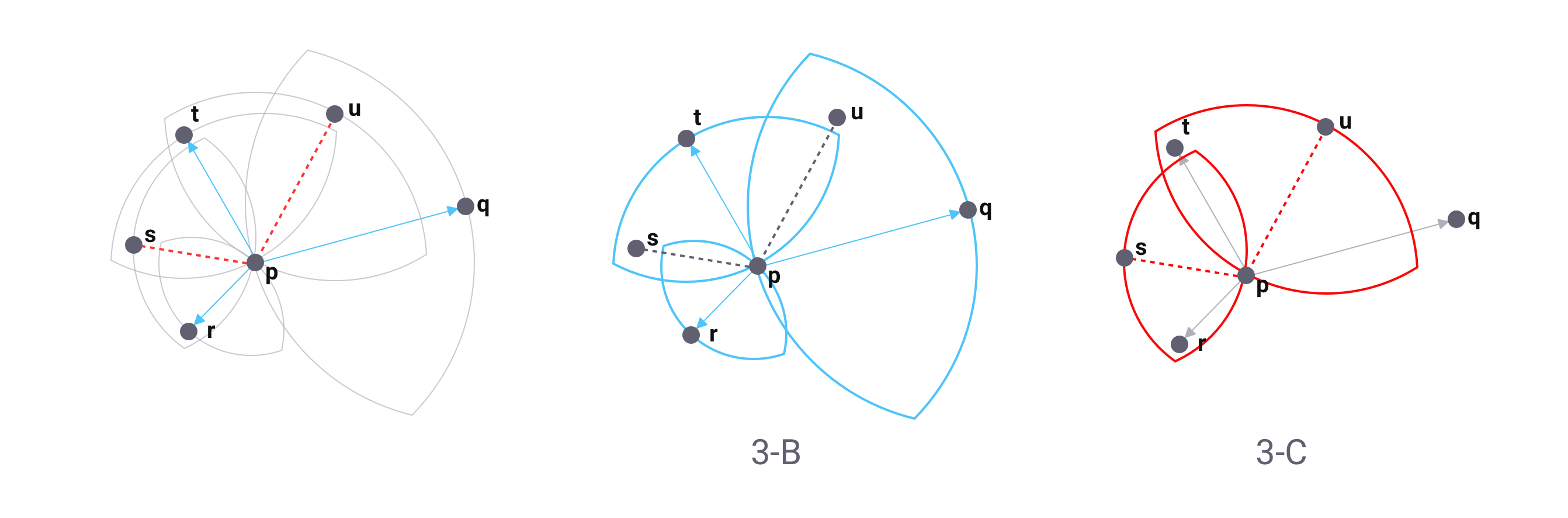
在这篇文章中主要介绍一下Candidate sampling在模型训练中的使用。
作为一个菜鸡的推荐炼丹师,前段时间看YouTube DNN的炼丹手册和双塔模型(DSSM)的配药指南。
发现在关于计算优化的部分YouTube DNN和DSSM都用了importance sampling进负样本的选取。
从网络结构的搭建和数据的选取来看,YouTube DNN怎么看都像是一个广义的word2vec。可是在word2vec模型的TensorFlow实现里面用的是NCE做计算性能的采样优化。
此外,对于YouTube DNN的负样本选取知乎上也有广泛的讨论。例如:知乎石塔西在《负样本为王:评Facebook的向量化召回算法》提出的hard模式和easy模式假设。
为了弄清楚不同网络采样的细节和采样的方法,我翻阅大量偏方,并且稍微做一下梳理。
在介绍candidate sampling之前我们先了解一下问题的背景。
1. Softmax 和 Cross Entropy
在多分类问题中,模型训练的目的是在训练集上学习到一个函数$F(x,y)$,该模型对于测试集和验证集上
每一个输入$x$,能够准确地预测到对应的类别$y$。
在一个类别数为$K$的多分类问题中,模型的softmax层对每一个类别计算可能的概率:
\[P(y_j|x) = \frac{\mathrm{exp}(h^\mathsf{T}v'_j)}{\sum^K_{i=1} \mathrm{exp}(h^\mathsf{T}v'_i) }\]
在softmax计算每一个输入类别概率的基础上,需要构建损失函数$J$来评估模型训练中学习得到$F(x,y)$
的效果。基于最朴素的想法,我们希望预测的类别$y_{prediction}$和真实的类别$y_{label}$具有更为接近的分布。
在评估两个分布的距离上,很自然地联想到使用$KL$散度,那么对于损失函数的相关定义如下:
在模型训练过程中,对应的输入为: $x$
样本对应标签的期望分布为$D(y|x)$
模型$F(x,y)$预测出的类别分布为$P(y|x)$
\[\begin{align}
J&= H(D(y|x),P(y|x)) \\
&= -D(y|x) \mathrm{ln}\frac{P(y|x)}{D(y|x)} \\
&= D(y|x)\mathrm{ln}D(y|x) - D(y|x)\mathrm{ln}P(y|x)
\end{align}\]
在模型训练过程中,对于相同数据集来说$D(y|x)\mathrm{ln}D(y|x)$ 可以看成是常数。
那么用来评估训练结果的损失函数可以表示为:
\[\begin{align}
\mathrm{min}\;(J) & = \mathrm{min}\;(D(y|x)\mathrm{ln}D(y|x) - D(y|x)\mathrm{ln}P(y|x)) \\
& = \mathrm{min}(\mathcal{K} - D(y|x)\mathrm{ln}P(y|x)) \\
& \sim \mathrm{min}(- D(y|x)\mathrm{ln}P(y|x)) \\
\end{align}\]
其中,$\mathcal{K}$ 为常数,那么损失函数的形式可以表示为期望分布$D(y|x)$和真实分布$P(y|x)$的交叉熵。
对所有$K$个类别求和,并且$D(y|x)$用标签$y$的值表示得到损失函数形式如下:
\[\begin{align}
J = -\sum_{i=1}^{K} y_i \mathrm{ln}(P(y_i|x)) \\
\end{align}\]
其中,当$i$对应的类别为正样本时$y_i=1$,当$i$为负样本时$y_i=0$,上述公式简化为:
\[\begin{align}
J &= - \mathrm{ln}\;P(y_{pos}|x) \\
& = - \mathrm{ln}\; \frac{\mathrm{exp}(h^\mathsf{T}v'_{pos})}{\sum^K_{i=1} \mathrm{exp}(h^\mathsf{T}v'_i) } \\
\end{align}\]
其中$y_{pos}$表示正样本类别。
2. candidate sampling
在上面的章节中,我们讨论了模型训练在多分类问题当中的损失函数。
那么如果在分类数$K$非常多的情况下,对于每个样本分类的预测都需要计算$K$个类别的概率。
显然,在分类数较小的情况下softmax的计算量可以接受,但是当分类数目扩增到百万甚至千万量级的情况下会单个样本的计算量过大。
假设,模型训练的数据集中有1000万条样本数据,其中分类的个数为百万量级。每个分类概率的计算为0.01ms
那么所需要的计算时间:
\[T_{cost} = 10000000 \times 1000000 \times 0.01 \div 1000 \ 3600 \ 24 = 1157.d\]
显然这个计算量级是没有办法被接受的。
那么基本思想就是在怎么样不影响计算效果的前提下减小计算量。
针对这个问题目前具备两种方法:
- softmax-based approach: 基于树结构的分层softmax,减少损失函数计算过程中计算量。
- sampling-based approach: 通过用采样的方式,通过计算样本的损失来代替全量的样本计算。
这里我们主要介绍sampling-based approach的方法,也就是candidate sampling。
回到损失函数的计算公式,并做进一步的简化:
\[\begin{align}
J & = - \mathrm{ln}\; \frac{\mathrm{exp}(h^\mathsf{T}v'_{pos})}{\sum^K_{i=1} \mathrm{exp}(h^\mathsf{T}v'_i) } \\
&= - h^\mathsf{T}v'_{pos} + \mathrm{ln}\sum^K_{i=1} \mathrm{exp}(h^\mathsf{T}v'_i)
\end{align}\]
在这个公式中用$\xi(w) = - h^\mathsf{T}v’_{pos}$,简化为:
\[\begin{align}
J &= \xi (w_{pos}) + \mathrm{ln}\sum^K_{i=1} \mathrm{exp}(-\xi(w_i))
\end{align}\]
对损失函数求导并计算梯度
\[\begin{align}
\nabla_\theta J &= \nabla_\theta \xi (w_{pos}) + \nabla_\theta \mathrm{ln}\sum^K_{i=1} \mathrm{exp}(-\xi(w_i))
\end{align}\]
因为$log(x)$的梯度为$\frac{1}{x}$
\[\begin{align}
\nabla_\theta J &= \nabla_\theta \xi (w_{pos}) + \frac{1}{\sum^K_{i=1} \mathrm{exp}(-\xi(w_i))} \nabla_\theta\sum^K_{i=1} \mathrm{exp}(-\xi(w_i))
\end{align}\]
然后我们把求导符号放到累加符内得到:
\[\begin{align}
\nabla_\theta J &= \nabla_\theta \xi (w_{pos}) + \frac{1}{\sum^K_{i=1} \mathrm{exp}(-\xi(w_i))} \sum^K_{i=1} \nabla_\theta \mathrm{exp}(-\xi(w_i))
\end{align}\]
并且有$\nabla_x \mathrm{exp}(x) = exp(x)$那么:
\[\begin{align}
\nabla_\theta J &= \nabla_\theta \xi (w_{pos}) + \frac{1}{\sum^K_{i=1} \mathrm{exp}(-\xi(w_i))} \sum^K_{i=1} \mathrm{exp}(-\xi(w_i)) \nabla_\theta (-\xi(w_i)
\end{align}\]
上面的公式可以重写成:
\[\begin{align}
\nabla_\theta J &= \nabla_\theta \xi (w_{pos}) + \sum^K_{i=1} \frac{\mathrm{exp}(-\xi(w_i))}{\sum^K_{i=1} \mathrm{exp}(-\xi(w_i))} \nabla_\theta (-\xi(w_i)
\end{align}\]
其中 $\frac{\mathrm{exp}(-\xi(w_i))}{\sum^K_{i=1} \mathrm{exp}(-\xi(w_i))}$就是输入上下文$c$在类别$i$上的的概率 $P(w_i | c)$
最终要计算的梯度形式如下:
\[\begin{align}
\nabla_\theta J &= \nabla_\theta \xi (w_{pos}) + \sum_{i=1}^K P(w_i|c) \nabla_\theta (-\xi(w_i) \\
& = \nabla_\theta \xi (w_{pos}) - \sum_{i=1}^K P(w_i|c) \nabla_\theta \xi(w_i)
\end{align}\]
根据最终的公式,我们可以将梯度的计算分为两部分:
在基于采样的优化当中,我们不需要计算所有类别的累加,只需要通过采样求到$\nabla_\theta \xi(w_i)$ 在分布$P(w_i|c)$的期望即可。
那么:
\[\begin{align}
\sum_{i=1}^K P(w_i|c)\nabla_\theta \xi(w_i) = \mathbb{E}_{w_i\sim P} [\nabla_\theta \xi(w_i)] \\
\end{align}\]
那么接下来的问题就变成了如何准确的计算梯度在概率分布$P(w_i)$上的期望:
\[\mathbb{E}_{w_i\sim P} [\nabla_\theta \xi(w_i)] \\\]
3. 常见的candidate sampling方法
在了解了candidate sampling方法的基本思想之后,我们怎么样计算期望$\mathbb{E_{w_i\sim P(w_i)}\nabla_\theta \xi(w_i)}$
成为一个值得考虑的问题。
3.1 Importance Sampling
对于任何概率分布我们计算期望$\mathbb{E}$的时候,可以采用蒙特卡洛方法,根据分布随机采样出一系列样本,然后计算样本
的平均值。
对于上述的例子,如果我们知道模型在不同类别的概率分布$P(w_i)$,在计算期望的时候可以直接采样出$m$个类别$w_1,…,w_m$
并且计算期望:
\[\mathbb{E}_{w_i \sim P}[\nabla_\theta\xi(w_i)] \approx \frac{1}{m}\sum_i^m \nabla_\theta\xi(w_i)\]
但是为了从分布$P$中采样样本,我们首先需要计算分布$P$。可是candidate sampling的目的就是为了避免计算分布$P$。
为了解决这个问题,能够使用的基本方法是重要性采样:
重要性采样(importance sampling)算法
假设我们需要计算概率密度函数$h(x)$在$\pi(x)$上的期望
\[\mu = \mathbb{E}_\pi{h(x)} = \int h(x)\pi(x)\]
那么重要性采样算法对应的形式如下:
(a) 首先,从分布 $g(\cdot)$ 中随机采样出 $m$ 个样本 $\mathrm{x}_1,…,\mathrm{x}_m$
(b) 计算重要性权重:
\[r(\mathrm{x}_i) = \frac{\pi(\mathrm{x}_i)}{g(\mathrm{x}_i)}, for\;\;j=1,...,m\]
(c) 近似期望 $\hat \mu$
\[\hat u=\frac{r_1 h(\mathrm{x}_1)+...+r_m h(\mathrm{x}_m)}{r(\mathrm{x}_1) + ... + r(\mathrm{x}_m)}\]
为了使得估计的时候误差更小,我们需要尽可能地使得$g(\cdot)$接近原来的$\pi(\mathrm{x})$。
这个时候上述公式可以描述为:
\[\hat \mu = \frac{1}{m} \{r(\mathrm{x}_1) h(\mathrm{x}_1) + ... + r(\mathrm{x}_m) h(\mathrm{x}_m)\}\]
根据上述描述,我们先预设一个分布$Q(w)$,为了使得$Q(w)$尽可能接近$P(w)$,一般可以采样一元分布。
对应的重要性权重 $r(w) = \frac{\mathrm{exp}(-\xi(w))}{Q(w)}$,那么对应的期望计算公式如下:
\[\begin{align}
\mathbb{E}_{w_i \sim P} & \approx \frac{r(w_1) \nabla_\theta \xi(w_1) + ... + r(w_m) \nabla_\theta \xi(w_m)}{r(w_i) +...+r(w_m)} \\
& = \frac{\sum_{i=1}^m r(w_i) \nabla_\theta \xi(w_i)}{\sum_{i=1}^m r(w_i)}
\end{align}\]
令 $R = \sum_{i=1}^m r(w_i)$ 得到
\[\begin{align}
\mathbb{E}_{w_i \sim P} & \approx \frac{1}{R} \sum_{i=1}^m r(w_i) \nabla_\theta \xi(w_i)
\end{align}\]
3.2 Noise Contrastive Estimation
在上面介绍完成Importance Sampling之后,我们来看一下Noise Contrastive Estimation(NCE)。抛开上面通过采样的思想
利用importance sampling近似计算多分类问题softmax损失的方法。
在NCE中,完全推翻上述方法并从试图从另外一个角度来解决多分类问题loss计算的问题——我们能否找到
一个损失函数用于替代原来的损失计算,从而避免softmax中归一化因子的计算。
NCE的基本思想是将多分类问题转换成为二分类问题,从噪音分布中采样,减少优化过程的计算复杂度。
在采样NCE方式计算loss的过程中,我们引入噪音分布$Q(w)$。这个噪音分布可以跟语境有关,也可以跟语境无关。
在噪音分布和语境无关的情况下,我们设置噪音分布的强度是真实数据分布的$m$倍。
那么对于训练数据$(c,w)$可以得到真实分布和噪音分布的概率:
\[\begin{align}
&P(y=1|w,c) = \frac{P_{train}(w|c)}{P_{train}(w|c) + mQ(w|c)}\\
\\
&P(y=0|w,c) = \frac{mQ(w|c)}{P_{train}(w|c) + mQ(w|c)}
\end{align}\]
得到
\[\begin{align}
P(w|c) = P_{train}(w|c) + mQ(w|c)
\end{align}\]
在原来的推导中:
\[\begin{align}
P(w|c) = \frac{\mathrm{exp}(h^\mathrm{T} v'_{w})}{\sum_{i=1}^K \mathrm{exp}(h^\mathrm{T} v'_{w_i})}
\end{align}\]
在NCE中为了避免对分母部分归一化因子的计算,将归一化因子表示为一个学习的参数$Z(c)$
\[\begin{align}
Z(c) = \sum_{i=1}^K \mathrm{exp}(h^\mathsf{T} v_{w'_i})
\end{align}\]
这个时候简化为:
\[\begin{align}
P(w|c) = \mathrm{exp}(h^\mathsf{T} v'_{w})
\end{align}\]
那么对于这个二分类问题计算Logistic regression损失:
\[\begin{align}
J = [ln \frac{\mathrm{exp}(h^\mathsf{T} v'_{w_i})}{\mathrm{exp}(h^\mathsf{T} v'_{w_i}) + mQ(w_i)}] + \sum_{j=1}^m [ln(1-ln \frac{\mathrm{exp}(h^\mathsf{T} v'_{w_{i,j}})}{\mathrm{exp}(h^\mathsf{T} v'_{w_{i,j}}) + mQ(w_{i,j})})]
\end{align}\]
在上述公式中,当$m\rightarrow \infty$, 上述公式和softmax的损失函数相似。
从NCE采样方法中可知:
- 基于softmax的多分类问题的损失函数可以表示成为logistic regression二分类的形式。
- NCE方法中,在梯度更新中放弃了对负样本参数的更新。
4. Tensorflow中candidate sampling的实现
理论很丰满,落地很骨感。
在了解完candidate sampling中的Importance sampling和Noise Contrastive Estimation的原理之后如果要工程落地还是需要依赖
可用的计算框架。在TensorFlow中就实现了这两个方法对应可以调用的API分别是:
- importance sampling: tf.nn.sampled_softmax_loss()
- Noise Contrastive Estimation: tf.nn.nce_loss()
4.1 tf.nn.sampled_softmax_loss()
在sampled_softmax_loss()中包含了两部分内容。
- _compute_sampled_logits()
- softmax_cross_entropy_with_logits_v2()
_compute_sampled_logits() 主要进行采样并计算logit。
softmax_cross_entropy_with_logits_v2() 主要计算softmax的交叉熵损失。
接下来我们主要看一下_compute_sampled_logits()的源码。
4.2 tf.nn.nce_loss()
在nce_loss()中包含了两部分内容。
- _compute_sampled_logits()
- sigmoid_cross_entropy_with_logits()
_compute_sampled_logits() 主要进行采样并计算logit。
sigmoid_cross_entropy_with_logits() 主要计算sigmoid的交叉熵损失。
接下来我们主要看一下_compute_sampled_logits()的源码。
def _compute_sampled_logits(weights,
biases,
labels,
inputs,
num_sampled,
num_classes,
num_true=1,
sampled_values=None,
subtract_log_q=True,
remove_accidental_hits=False,
partition_strategy="mod",
name=None,
seed=None):
if isinstance(weights, variables.PartitionedVariable):
weights = list(weights)
if not isinstance(weights, list):
weights = [weights]
with ops.name_scope(name, "compute_sampled_logits",
weights + [biases, inputs, labels]):
if labels.dtype != dtypes.int64:
labels = math_ops.cast(labels, dtypes.int64)
labels_flat = array_ops.reshape(labels, [-1])
# Sample the negative labels.
# sampled shape: [num_sampled] tensor
# true_expected_count shape = [batch_size, 1] tensor
# sampled_expected_count shape = [num_sampled] tensor
if sampled_values is None:
sampled_values = candidate_sampling_ops.log_uniform_candidate_sampler(
true_classes=labels,
num_true=num_true,
num_sampled=num_sampled,
unique=True,
range_max=num_classes,
seed=seed)
# NOTE: pylint cannot tell that 'sampled_values' is a sequence
# pylint: disable=unpacking-non-sequence
sampled, true_expected_count, sampled_expected_count = (
array_ops.stop_gradient(s) for s in sampled_values)
# pylint: enable=unpacking-non-sequence
sampled = math_ops.cast(sampled, dtypes.int64)
# labels_flat is a [batch_size * num_true] tensor
# sampled is a [num_sampled] int tensor
all_ids = array_ops.concat([labels_flat, sampled], 0)
# Retrieve the true weights and the logits of the sampled weights.
# weights shape is [num_classes, dim]
all_w = embedding_ops.embedding_lookup(
weights, all_ids, partition_strategy=partition_strategy)
if all_w.dtype != inputs.dtype:
all_w = math_ops.cast(all_w, inputs.dtype)
# true_w shape is [batch_size * num_true, dim]
true_w = array_ops.slice(all_w, [0, 0],
array_ops.stack(
[array_ops.shape(labels_flat)[0], -1]))
sampled_w = array_ops.slice(
all_w, array_ops.stack([array_ops.shape(labels_flat)[0], 0]), [-1, -1])
# inputs has shape [batch_size, dim]
# sampled_w has shape [num_sampled, dim]
# Apply X*W', which yields [batch_size, num_sampled]
sampled_logits = math_ops.matmul(inputs, sampled_w, transpose_b=True)
# Retrieve the true and sampled biases, compute the true logits, and
# add the biases to the true and sampled logits.
all_b = embedding_ops.embedding_lookup(
biases, all_ids, partition_strategy=partition_strategy)
if all_b.dtype != inputs.dtype:
all_b = math_ops.cast(all_b, inputs.dtype)
# true_b is a [batch_size * num_true] tensor
# sampled_b is a [num_sampled] float tensor
true_b = array_ops.slice(all_b, [0], array_ops.shape(labels_flat))
sampled_b = array_ops.slice(all_b, array_ops.shape(labels_flat), [-1])
# inputs shape is [batch_size, dim]
# true_w shape is [batch_size * num_true, dim]
# row_wise_dots is [batch_size, num_true, dim]
dim = array_ops.shape(true_w)[1:2]
new_true_w_shape = array_ops.concat([[-1, num_true], dim], 0)
row_wise_dots = math_ops.multiply(
array_ops.expand_dims(inputs, 1),
array_ops.reshape(true_w, new_true_w_shape))
# We want the row-wise dot plus biases which yields a
# [batch_size, num_true] tensor of true_logits.
dots_as_matrix = array_ops.reshape(row_wise_dots,
array_ops.concat([[-1], dim], 0))
true_logits = array_ops.reshape(_sum_rows(dots_as_matrix), [-1, num_true])
true_b = array_ops.reshape(true_b, [-1, num_true])
true_logits += true_b
sampled_logits += sampled_b
if remove_accidental_hits:
acc_hits = candidate_sampling_ops.compute_accidental_hits(
labels, sampled, num_true=num_true)
acc_indices, acc_ids, acc_weights = acc_hits
# This is how SparseToDense expects the indices.
acc_indices_2d = array_ops.reshape(acc_indices, [-1, 1])
acc_ids_2d_int32 = array_ops.reshape(
math_ops.cast(acc_ids, dtypes.int32), [-1, 1])
sparse_indices = array_ops.concat([acc_indices_2d, acc_ids_2d_int32], 1,
"sparse_indices")
# Create sampled_logits_shape = [batch_size, num_sampled]
sampled_logits_shape = array_ops.concat(
[array_ops.shape(labels)[:1],
array_ops.expand_dims(num_sampled, 0)], 0)
if sampled_logits.dtype != acc_weights.dtype:
acc_weights = math_ops.cast(acc_weights, sampled_logits.dtype)
sampled_logits += gen_sparse_ops.sparse_to_dense(
sparse_indices,
sampled_logits_shape,
acc_weights,
default_value=0.0,
validate_indices=False)
if subtract_log_q:
# Subtract log of Q(l), prior probability that l appears in sampled.
true_logits -= math_ops.log(true_expected_count)
sampled_logits -= math_ops.log(sampled_expected_count)
# Construct output logits and labels. The true labels/logits start at col 0.
out_logits = array_ops.concat([true_logits, sampled_logits], 1)
# true_logits is a float tensor, ones_like(true_logits) is a float
# tensor of ones. We then divide by num_true to ensure the per-example
# labels sum to 1.0, i.e. form a proper probability distribution.
out_labels = array_ops.concat([
array_ops.ones_like(true_logits) / num_true,
array_ops.zeros_like(sampled_logits)
], 1)
return out_logits, out_labels
参考资料
[1] 从最优化的角度看待Softmax损失函数
[2] On word embeddings - Part 2: Approximating the Softmax
[3] 重要性采样
[4] Noise Contrastive Estimation